Case Study · 03
Is ML actually beating physics at weather?
A live evaluation system comparing the National Weather Service's physics-based forecasts against ECMWF's AIFS machine-learning model — with disagreement alerts and a running 30-day accuracy scoreboard.
Context
Weather forecasting just changed. For the first time, a machine-learning model — ECMWF's Artificial Intelligence Forecasting System, or AIFS — produces operational forecasts that match or beat the physics-based numerical models the field has relied on for decades.
That's a substantial claim. The interesting question isn't whether to believe it — it's how to check. Not on a research benchmark, but on real forecasts for real locations, day after day.
This project is an evaluation system: same location, two forecast sources, displayed side by side, with the divergences flagged automatically and the accuracy of each model tracked against ground truth over time.
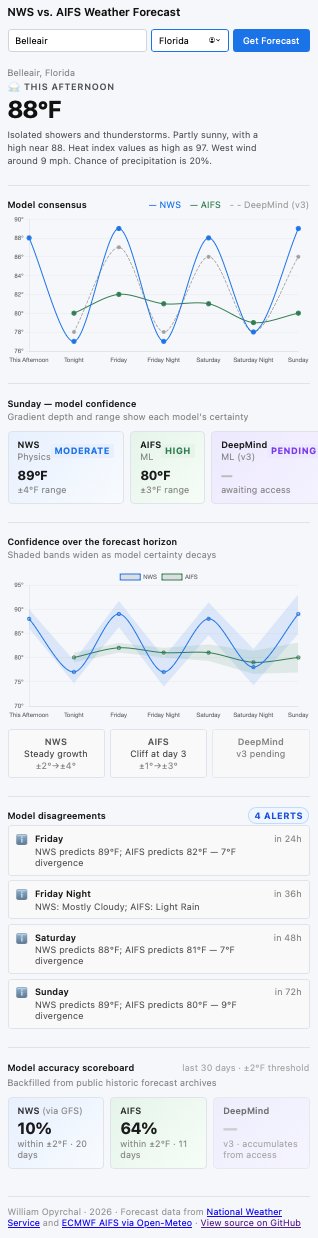
The system
Two forecasts. One scoreboard.
The app pulls forecasts from two sources for a user-selected location and renders them on a shared set of axes — same horizon, same units, same time ranges. Then it does three things a side-by-side viewer alone wouldn't:
1. A consensus view with confidence bands
Each model's forecast carries its own uncertainty. NWS shows a steady widening of confidence as the horizon extends; AIFS shows a sharper "cliff" at around day 3 where its certainty drops off. Both bands rendered together — the user sees not just the predictions but how much each model trusts itself.
2. Disagreement alerts
When the two models predict materially different outcomes for the same day — say,
NWS 89°F vs AIFS 82°F — the system surfaces the divergence as an alert
with the magnitude. These are the cases that matter: agreement is uninteresting,
disagreement is where one of the models is about to be wrong.
3. A running accuracy scoreboard
For each location a user searches, the system backfills both models' next-day
forecasts from public historic archives and scores them against the observed daily
high — live, on demand, against a ±2°F threshold over a 30-day window.
The scoreboard isn't a fixed result; it recomputes per location every time. A
representative snapshot for one city:
NWS · Physics
10%
within ±2°F · 20 days scored
AIFS · ML
64%
within ±2°F · 11 days scored
DeepMind · WeatherNext
—
awaiting API access
These are early numbers on a small per-location sample, and the scoring methodology is still being hardened — see the writeup for the open questions. The point of the scoreboard isn't the headline percentage; it's that the comparison is measurable at all, on real forecasts for real places, in a way anyone can rerun from public data. That's what the project was built to make possible.
Workflow
Build fast. Verify slowly.
This project was a deliberate experiment in a different AI-assisted workflow than the design-first approach I used on AskMickey. The goal: see how fast I could ship a working evaluation system using AI tools heavily for code generation — and what discipline I'd need to keep the result trustworthy.
The answer to the second question turned out to matter more than the first. Producing code quickly with an AI assistant is easy. Knowing whether the code does what you asked it to is the engineering work — and on an evaluation system, that work compounds: every claim the app makes about model accuracy has to be traceable to data you can defend.
The discipline wasn't in the writing. It was in the verification — checking each piece against the source data, the actual API responses, and the rendered output before trusting it.
Concretely, that meant:
- API responses inspected directly against documentation — never trusted from AI-generated handler code alone.
- Forecast values cross-checked against the official NWS and ECMWF outputs before render.
- Unit and timezone conversions tested with edge cases — the single largest source of silent bugs in any weather application.
- Accuracy scoring methodology validated against a small hand-checked sample before backfilling at scale.
- The "model accuracy scoreboard" numbers are reproducible from public historic archives — anyone can rerun the scoring.
The result is a system I can defend, built faster than I could have built it alone. But the speed of the build isn't the takeaway — the discipline of the verification is. That's the part of AI-assisted development that generalizes.
Front-end
- JavaScript
- HTML / CSS
- Custom chart rendering
Data sources
- NWS public API
- ECMWF AIFS via Open-Meteo
- DeepMind WeatherNext (pending)
Evaluation
- Historic-archive backfill
- ±2°F threshold scoring
- Disagreement detection
Workflow
- AI-assisted code generation
- Verification loop discipline
- GitHub Pages, static only
Artifacts